Indexing is a critical feature in MongoDB, especially when managing large collections with tens of thousands of documents. Without indexes, MongoDB would need to perform a full collection scan to find specific data, much like a librarian searching every book in a library. Indexes in MongoDB, however, allow for rapid document retrieval, similar to how the Dewey Decimal system helps a librarian locate books efficiently.
2.2.1. Indexing
_id Index
Automatic Indexing:
When you create a collection in MongoDB, a primary key called_idis automatically generated for each document. This key is indexed using a B+Tree structure to optimize search operations. The_iduniquely identifies each document and can be used to efficiently locate it.ObjectId:
The_idfield is typically of typeObjectId, a 12-byte identifier. Its size ensures unique identification across distributed systems, like sharded clusters. Users can override the_idfield with their own values, which might increase the key size, potentially impacting performance.Primary Index:
The primary index maps the_idto the corresponding BSON document through a B+Tree structure. As MongoDB has evolved, the way this mapping is handled has also changed, which will be explored in the following sections.
Secondary Indexes
Custom Indexing:
MongoDB allows the creation of secondary B+Tree indexes on any field within a collection. These indexes point back to BSON documents that satisfy the index criteria, enabling fast data retrieval using various fields, not just_id. Without secondary indexes, MongoDB would need to scan the entire collection, field by field, to locate specific data.Index Size:
The size of a secondary index depends on two factors: the size of the indexed field (key size) and the size of the document pointer. The efficiency and storage requirements of these indexes can vary depending on the MongoDB version and storage engine in use.
2.2.2. Evolution of MongoDB’s Indexing
MMAPv1
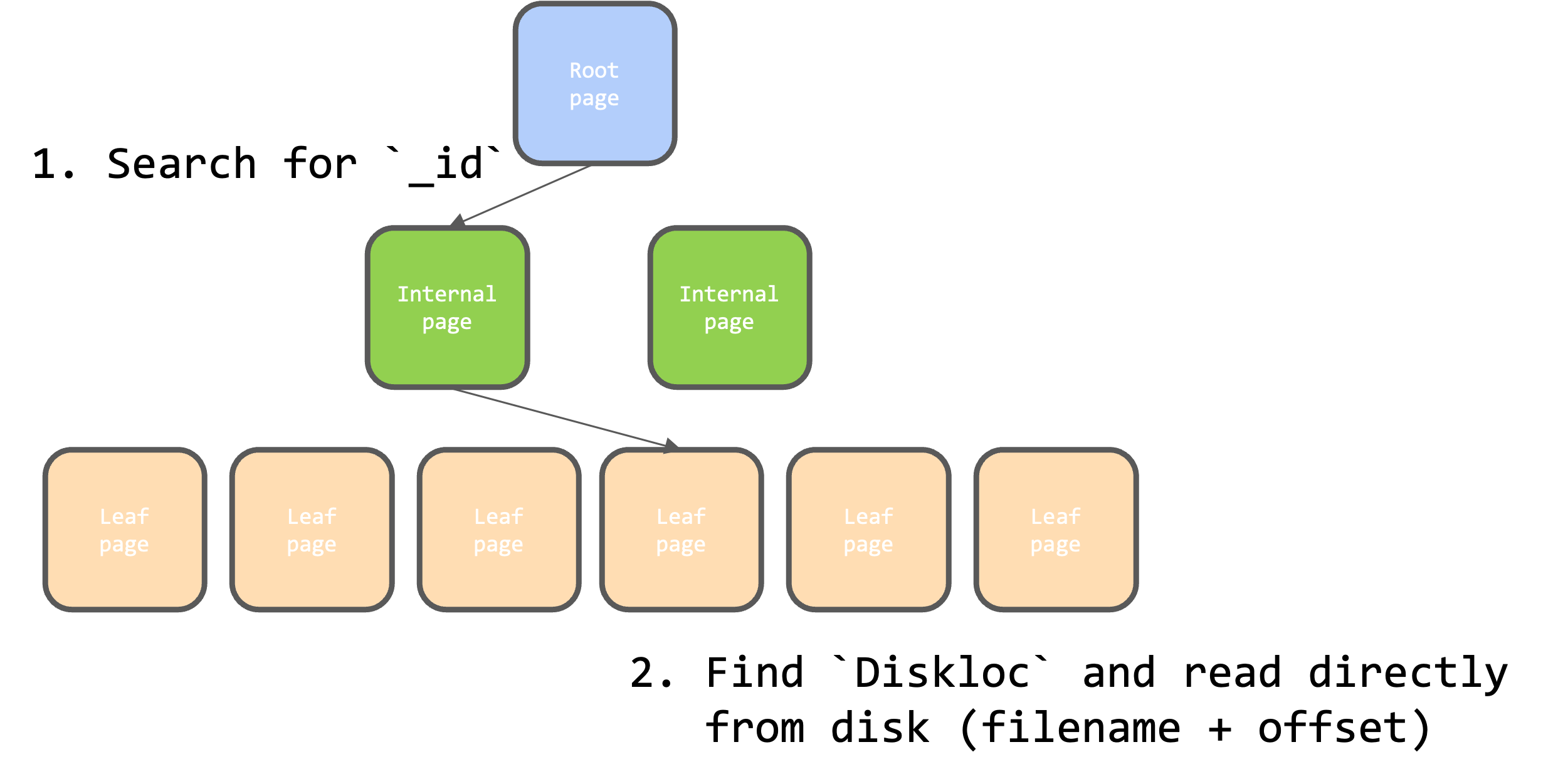
Diskloc:
Initially, MongoDB used the MMAPv1 storage engine, where BSON documents were stored directly on disk without compression. The_idprimary key index mapped to aDisklocvalue, a pair of 32-bit integers representing the file number and offset on disk where the document was stored.
- Challenges:
WhileDisklocallowed for O(1) retrieval of documents, it was difficult to maintain as documents were inserted or updated. Updates that changed document sizes required recalculating offsets for all subsequent documents, leading to inefficiencies. Additionally, MMAPv1 employed a single global database lock for writes, which severely limited concurrent write operations.
WiredTiger
- MongoDB v4.2-5.2:
In 2014, MongoDB acquired WiredTiger, which became the default storage engine. WiredTiger introduced several enhancements, such as document-level locking and compression, allowing for more efficient concurrent writes within the same collection. BSON documents in WiredTiger are compressed and stored in a hidden index, where leaf pages are recordId-BSON pairs. This design allows for more efficient I/O operations, improving overall performance.
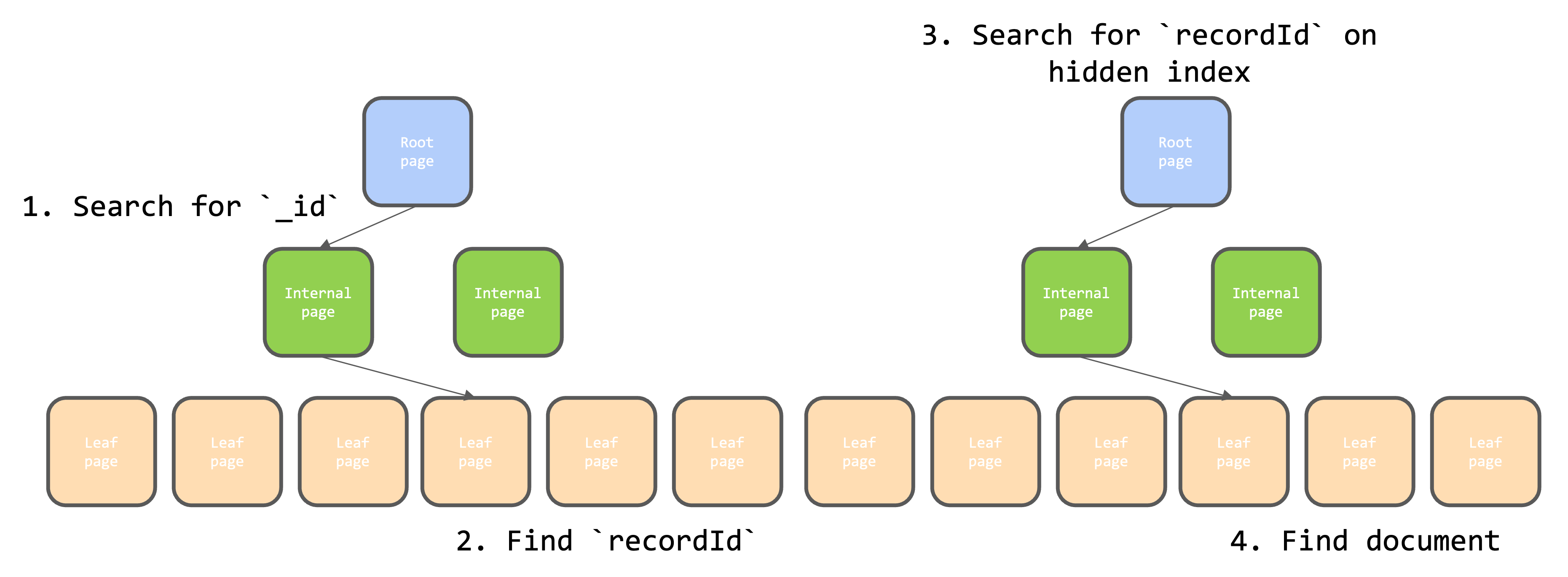
Double Lookup Cost
With WiredTiger, the primary index_idand secondary indexes were modified to point torecordIdinstead ofDiskloc. This change, while beneficial, introduced a double lookup cost: retrieving a document required first finding therecordIdvia the_idindex and then performing a second lookup on the hidden WiredTiger index to access the BSON document. Despite this overhead, the size of both primary and secondary indexes remained predictable, thanks to the 64-bitrecordId.
- MongoDB v5.3~:
In June 2022, MongoDB introduced clustered collections, where the primary_idindex became a clustered index. In this setup, all fields are stored in the leaf page, enabling index-only scans. This change means that looking up a document by_iddirectly returns the BSON document, eliminating the need for a second lookup.
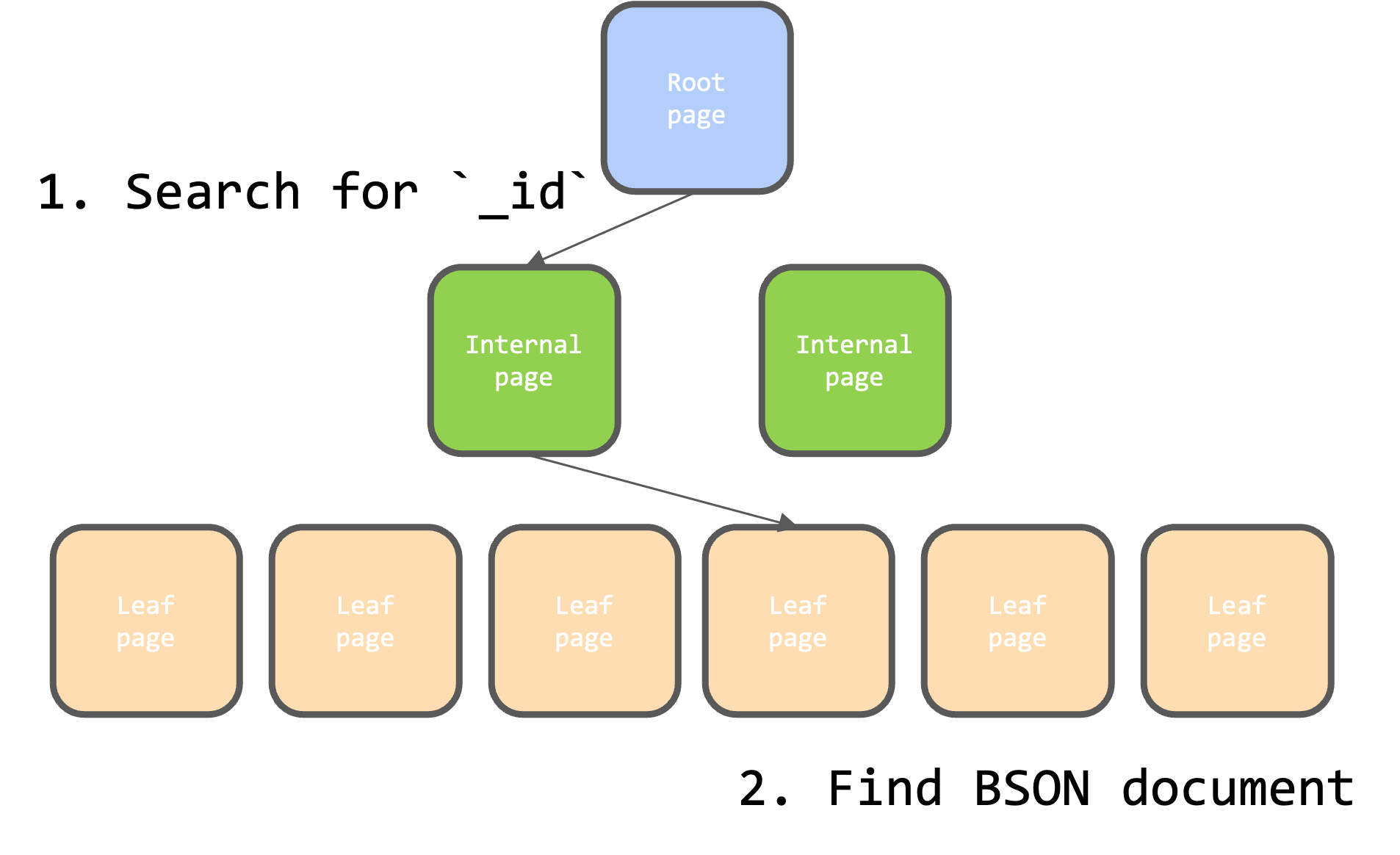
Impact on Secondary Indexes
With clustered collections, secondary indexes now point to the_idfield rather thanrecordId. This change increases the size of secondary indexes, as they must store the 12-byte_idvalue (or more if overridden by the user). This can significantly bloat secondary indexes, impacting performance and memory usage, especially in data-intensive applications.