3.3. COMPRESSION
I/O is the main bottleneck if the DBMS fetches data from disk during query execution.
To mitigate this, the DBMS can compress pages to maximize the efficiency of the data moved per I/O operation.
Goals
- Fixed-Length Values:
- The compression process should produce fixed-length values.
- The only exception is variable-length data, which should be stored in a separate pool.
- Postpone Decompression:
- Decompression should be delayed as long as possible during query execution, a technique known as late materialization.
- Lossless Compression:
- The compression scheme must ensure that no data is lost during the process.
3.3.1 Compression Granularity
- Block-level
- Compress a block of tuples for the same table.
- Tuple-level
- Compress the contents of the entire tuple.
- Attribute-level
- Compress a single attribute within one tuple.
- Can target multiple attributes for the same tuple.
- Column-level
- Compress multiple values for one or more attributes stored for multiple tuples.
3.3.2. Compression Algorithms
WiredTiger, used by MongoDB, supports compression of data on disk across three specific areas. There are two primary compression algorithms available, each with its own trade-offs:
- The default compression algorithm used by WiredTiger.
- It is used to compress the page.
- It provides fast compression with low CPU overhead, making it suitable for general-purpose use where performance is a priority over maximum compression.
- A widely-used compression algorithm that offers higher compression ratios than
snappy. - It requires more CPU resources and time, making it better suited for scenarios where storage efficiency is more important than performance.
- A widely-used compression algorithm that offers higher compression ratios than
- A modern compression algorithm that balances high compression ratios with relatively fast processing times.
- It generally provides better compression than
snappyand is more efficient in terms of speed compared tozlib, but still requires more CPU thansnappy.
none- This option disables compression entirely, which may be desirable in cases where compression overhead is not acceptable or storage space is not a concern.
3.3.3. Compression Areas
WiredTiger allows compression in the following areas:
- Collection Data: Compresses the data within collections.
- Index Data: Compresses the data within indexes.
- Journal Data: Compresses the data used for ensuring redundancy and recoverability while being written to long-term storage.
3.3.4. Prefix Compression
MongoDB WiredTiger’s row-store storage format supports a variant of prefix compression in the disk layout by identifying prefixes between adjacent keys, similar to delta-encoding:
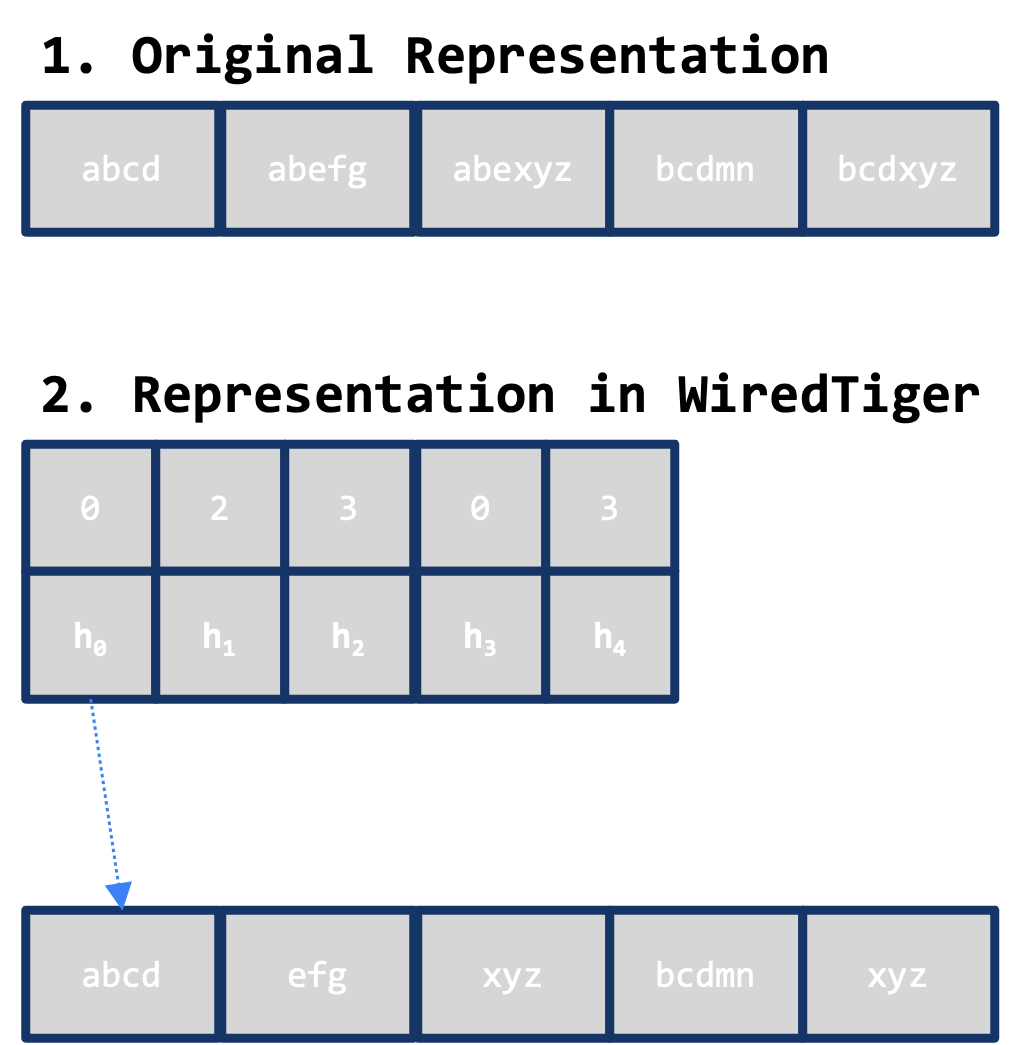
Prefix Handling:
- Each key stores only the suffix key bytes and the number of prefix bytes common with the previous key.
- The first key in the node is stored fully; following keys store only the suffix.
Key Decompression:
- Decompression requires finding a fully instantiated key and then walking forward to build the key.
3.3.5. Suffix Truncation
WiredTiger implements a suffix truncation technique:
- Example:
- When a node splits between keys
"abfe"and"bacd","b"is promoted to the parent node instead of the entire key"bacd".
- When a node splits between keys
3.3.6 Key Instantiation Techniques
WiredTiger supports two key instantiation techniques to help with search and insertion:
Best Prefix Group:
- Maintains a best slot whose base key can be used to decompress the most keys without scanning.
- The most-used page key prefix is the longest group of compressed key prefixes that can be built from a single, fully instantiated key.
Roll-forward Distance Control:
- Instantiates some keys in advance to avoid slow searches.
- Limits how far the cursor must roll backward by setting a “skipping distance.”
- For each set of keys within this distance, WiredTiger instantiates the first key.